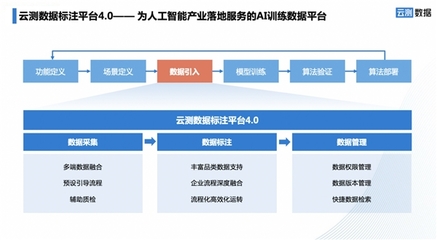
在人工智能迅猛發展的浪潮中,高質量的訓練數據已成為驅動AI模型進化的核心燃料。一款宣稱能夠將數據標注效率提升200%、并降低60%以上成本的數據服務工具橫空出世,在業界引發了廣泛關注。它究竟有何底氣,敢自稱“AI訓練數據最強工具”?其背后又蘊含著怎樣的技術與商業邏輯?
一、 數據瓶頸與行業痛點
當前,AI產業的繁榮與數據標注的“苦力活”形成了鮮明對比。模型精度越高,對訓練數據的規模、質量、多樣性和標注精度要求就越高。傳統的數據處理方式面臨幾大核心挑戰:人工標注成本高昂且效率低下,一致性難以保證;復雜場景(如自動駕駛的3D點云、醫療影像的病灶分割)的標注門檻極高;數據隱私與安全合規要求日益嚴格。這些痛點嚴重制約了AI項目的研發速度與規模化落地。
二、 破局之匙:技術驅動的智能化數據服務
這款引發熱議的工具,其核心突破在于將前沿AI技術深度融入數據生產的全鏈路,實現了從“人海戰術”到“人機協同”乃至“智能自動化”的范式轉變。
- 智能預標注與自動增強:工具內置了經過預訓練的強泛化性模型,能夠對原始數據進行初步的智能識別與標注(預標注),標注員只需進行修正和審核,工作量大幅減少。它能自動進行數據清洗、去重、增強(如旋轉、裁剪、添加噪聲),有效擴充高質量數據集。
- 復雜任務專用引擎:針對文本、語音、2D/3D圖像、視頻等不同模態數據,以及實體識別、情感分析、目標檢測、語義分割等不同任務,工具提供了高度優化的專用標注界面與算法輔助,極大降低了復雜標注的操作難度。
- 全鏈路質量管理與協同平臺:它不僅僅是一個標注工具,更是一個項目管理平臺。內置的質量控制算法能實時監測標注一致性,智能分配難例復審。云端協同工作流使得全球分布的標注團隊能夠無縫協作,項目管理透明高效。
- 隱私計算與合規保障:采用聯邦學習、差分隱私、數據脫敏等技術,確保原始數據不出域,或在嚴格加密環境下進行處理,滿足了金融、醫療等行業對數據安全的嚴苛要求。
正是這些技術的深度融合,使得“效率提升200%”和“成本降低60%”并非夸大其詞。效率提升源于自動化對人工的替代與輔助;成本降低則綜合了人力節省、流程優化、錯誤減少及數據利用率提升等多重因素。
三、 深遠影響與未來展望
這款工具的出現,標志著互聯網數據服務正從勞動密集型向技術密集型升級。它的影響是深遠的:
- 對AI研發者:大幅降低了獲取高質量數據的門檻與周期,讓初創公司和小團隊也能訓練出高性能模型,加速創新試錯。
- 對數據服務行業:推動了行業向更高附加值、更技術驅動的方向演進,促使傳統標注企業進行技術升級。
- 對AI產業生態:通過提供更優質、更經濟的“數據養料”,促進更大規模、更復雜的AI應用落地,形成良性循環。
最強工具的稱號也需要經受時間與復雜場景的考驗。未來的競爭將集中在算法的泛化能力、對長尾場景和極端案例的處理水平、以及對多模態融合標注的支持程度上。數據服務的終極目標,是成為AI基礎設施中如水電般可靠、高效的一環。
結論而言,這款以驚人效能數據吸引眼球的工具,其真正的“來頭”在于它代表了數據生產領域的智能化革命。它不僅是提升效率的利器,更是解放AI生產力、推動產業整體躍遷的關鍵拼圖。在數據決定AI高度的時代,擁有這樣的“最強工具”,無疑意味著搶占了發展的制高點。